
T-Mobile Poland — Business Process Optimization
Application of Data Science and Machine Learning in Business Process Optimization and Predictive Modeling
The Problem
As one of the largest mobile network operators in Poland with over 10 million customers, T-Mobile Poland possesses a substantial volume of data often referred to as ‘Big Data’. What sets T-Mobile apart is its conscious approach to the value of this data, which prompted our collaborative project. T-Mobile actively sought ways to leverage this data to optimize business processes, particularly in the realm of product and service sales.
The Solution
To address this challenge, we proposed a data analysis and predictive modeling system based on Machine Learning. The analytical system consisted of several key components:
Security
The first crucial step involved establishing a secure environment for working with sensitive data. Our DevOps team created a solution based on VPN tunnels and multiple layers of authorization, enabling remote work with sensitive data from T-Mobile’s data warehouse.
Data Preparation (Data Engineering)
The next step involved the preparation and analysis of the accessible data. The data stored in the Hadoop system required proper aggregation and preselection based on relevant attributes pertinent to the problem. This process involved collaboration between T-Mobile’s Big Data team and teonite’s Data Science team.
Data Analysis / Feature Selection
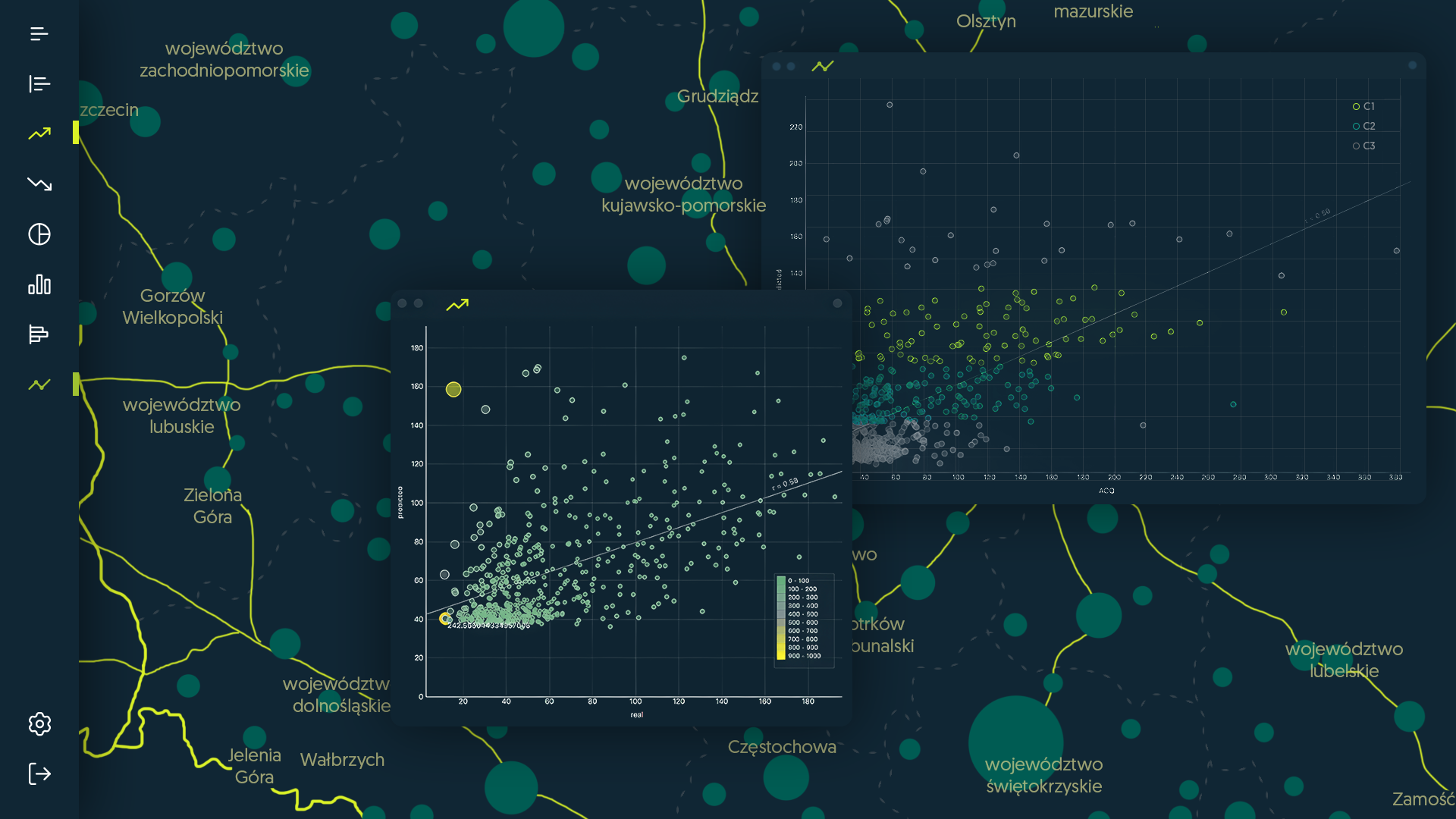
With the prepared data, we conducted analyses that included the visualization of attributes, correlation analysis, determination of quality and resolution, and metric development. This phase allowed us to identify issues related to data quality and modeling assumptions. One such challenge was the excessive depth of aggregation, resulting in numerous missing values. Through experimentation, we found an appropriate level of aggregation to create a dataset suitable for machine learning modeling.
Predictive Modeling
We implemented and tested various versions of the model, utilizing Jupyter Notebook within the TMPL infrastructure. Regression algorithms, including Lasso, ElasticNet, Ridge Regression, and Gradient Boosting, were tested. The final model implementation employed the XGBoost algorithm in Python, known for its “boosting” approach using a tree ensemble.
Presentation of Results
The final and vital aspect of the project was presenting the research findings in a business-friendly format. We employed various tools for this purpose, including interactive model deployment (Jupyter Notebooks), visualization using interactive maps with integrated information (Google Maps), and an interactive environment for result analysis (Orange Data Studio).
Challenges
Legal and Regulatory Considerations
Adherence to data privacy regulations and anonymization of personal data were imperative due to legal restrictions governing data use.
Data Quality
Ensuring the quality of data related to subscriber counts and traffic intensity in specific areas required selecting representative measurement points and data transformation.
Feature Engineering
Addressing the lack of strong correlations between the target variable (new contracts signed in stores) and explanatory variables, along with limitations affecting the model’s ability to differentiate predicted locations, was a key challenge.
Results
The project delivered two key outcomes:
Research Report
This report documented the research findings, insights, visualizations, and explanations of the designed model.
Analytical Framework
The entire data processing workflow, along with the trained Machine Learning model capable of generating predictions.
“The project conducted by teonite provided valuable insights into T-Mobile’s data assets. Our agile approach combined with extensive knowledge in Data Science ensured the success of the entire endeavor.”
—Michał Krauze, Head Of New Business and Innovation at T-Mobile Poland*
We are ready for more Machine Learning challenges! Contact us for further information.